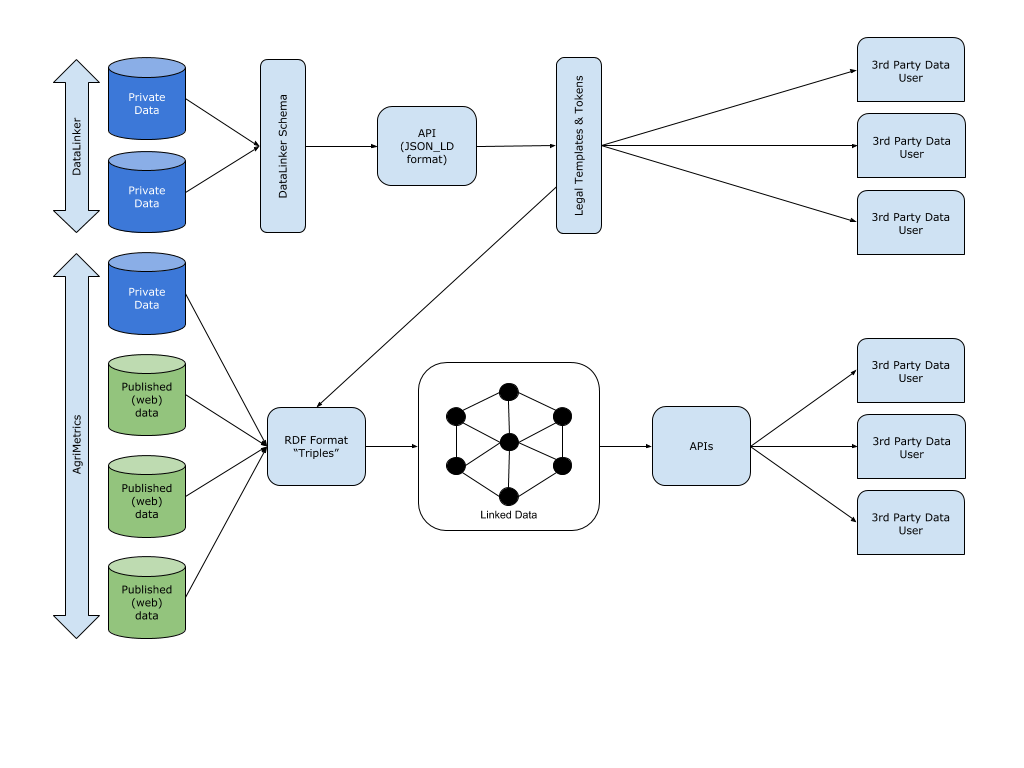
Last week the UK Agriculture and Horticulture Development Board (AHDB) announced an industry consultation to develop a set of principles (code) to promote the sharing of farm data. Happily, we at Rezare UK have been awarded the contract to run this project based on our unique agridata expertise and our significant experience in developing a […]